 TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-300×180.png 300w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-768×461.png 768w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-1536×921.png 1536w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-2048×1228.png 2048w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-800×480.png 800w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-1160×696.png 1160w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal.png 2114w” sizes=”(max-width: 1024px) 100vw, 1024px”>
TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-300×180.png 300w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-768×461.png 768w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-1536×921.png 1536w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-2048×1228.png 2048w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-800×480.png 800w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal-1160×696.png 1160w, https://TheTechMedia.com/wp-content/uploads/2023/03/chat-gpt-4-open-ai-the-tech-portal.png 2114w” sizes=”(max-width: 1024px) 100vw, 1024px”>OpenAI, the parent behind the infamous AI chatbot ChatGPT, has announced the release of a new multimodal AI, GPT-4. Multimodal, since it can take both images and text as inputs to produce a text-based output. According to OpenAI, GPT-4 is “less capable than humans in many real-world scenarios”, though at the same time, can exhbit “human-level performance on various professional and academic benchmarks”.
In terms of availability, GPT-4 is being available to OpenAI’s paying customers, through ChatGPT Plus. Developers can sign up on a waitlist to access the API. Pricing is $0.03 per 1,000 “prompt” tokens (about 750 words) and $0.06 per 1,000 “completion” tokens (again, about 750 words). Additionally, OpenAI is also open-sourcing OpenAI Evals, the framework behind its automated evaluation of AI model performance, to allow anyone to report shortcomings in its AI models to help guide further improvements.
Apparantly, GPT-4 was kind of already being used across various enterprise and even consumer-facing software. For example, Microsoft confirmed today that Bing Chat, its chatbot tech co-developed with OpenAI, is running on GPT-4. Other early adopters include Stripe, which is using GPT-4 to scan business websites and deliver a summary to customer support staff. Duolingo built GPT-4 into a new language learning subscription tier.
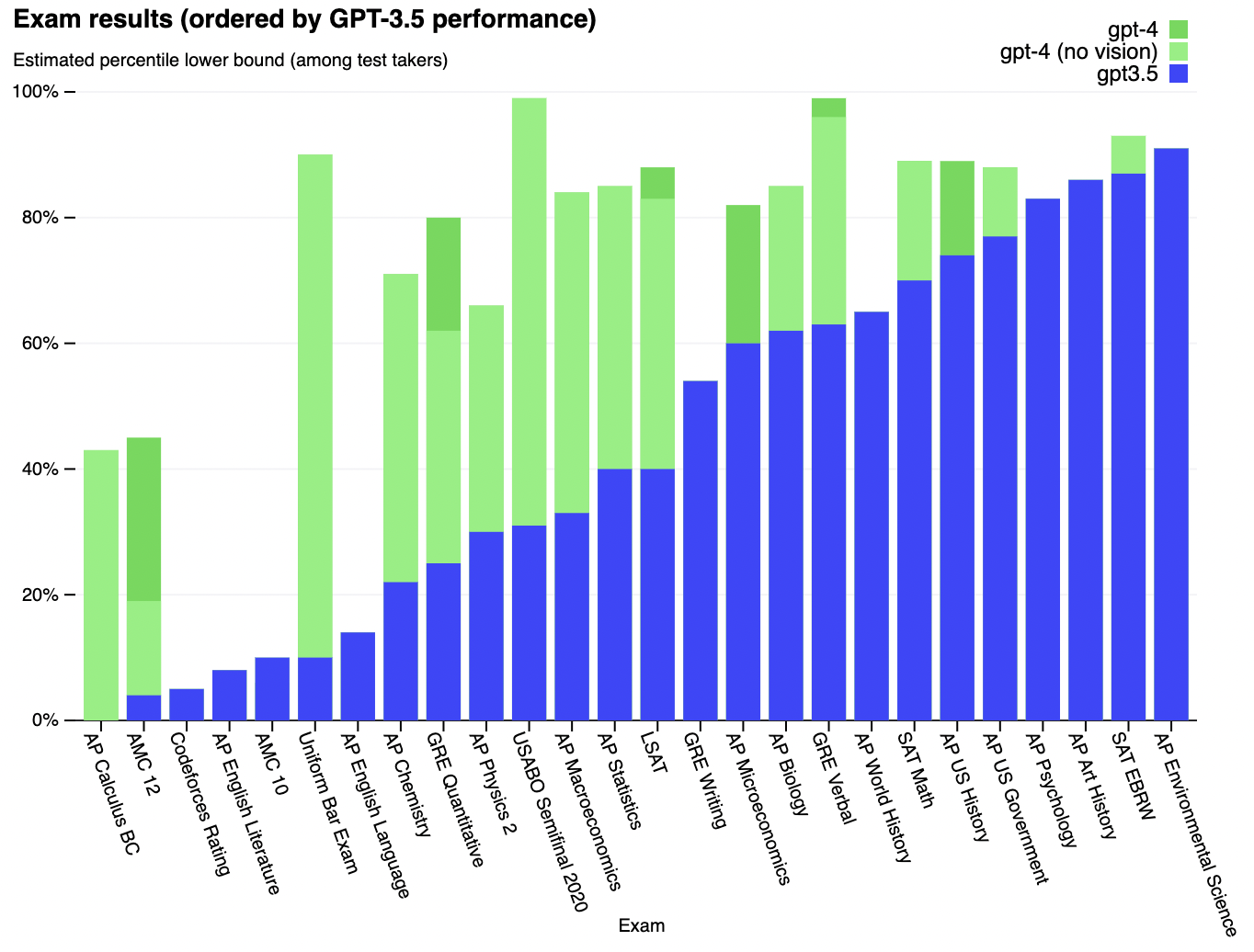
GPT-4 is an improvement over the existing GPT-3.5 model, though the improvements will only be visible when it is pushed into performing more complicated tasks. In usualy conversations with ChatGPT, you would hardly notice these improvements. For example, GPT-4 passes a simulated bar exam with a score around the top 10% of test takers; in contrast, GPT-3.5’s score was around the bottom 10%. OpenAI says that it has spent 6 months “iteratively aligning” GPT-4 using lessons from its “adversarial testing program” as well as ChatGPT, resulting in these best-ever results (though far from perfect) on factuality, steerability, and refusing to go outside of guardrails.
To understand the difference between the two models, OpenAI tested on a variety of benchmarks, including simulating exams that were originally designed for humans. This was done by using the most recent publicly-available tests (in the case of the Olympiads and AP free response questions) or by purchasing 2022–2023 editions of practice exams. GPT-4 did not undergo any specific training for these exams, and in light of that, the test results do seem impressive.
 TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-300×228.png 300w, https://TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-1011×768.png 1011w, https://TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-768×583.png 768w, https://TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-800×608.png 800w, https://TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-1160×881.png 1160w” sizes=”(max-width: 1364px) 100vw, 1364px”>
TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-300×228.png 300w, https://TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-1011×768.png 1011w, https://TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-768×583.png 768w, https://TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-800×608.png 800w, https://TheTechMedia.com/wp-content/uploads/2023/03/Screenshot-2023-03-15-at-12.18.08-PM-1160×881.png 1160w” sizes=”(max-width: 1364px) 100vw, 1364px”>
By the looks of it (we haven’t tested it ourselves) and some initial test results, GPT-4 does look like a considerable improvement over its predecessor. GPT-4 can accept a prompt of text and images, which—parallel to the text-only setting—lets the user specify any vision or language task. Specifically, it generates text outputs (natural language, code, etc.) given inputs consisting of interspersed text and images. Over a range of domains—including documents with text and photographs, diagrams, or screenshots—GPT-4 exhibits similar capabilities as it does on text-only inputs.
However, one of the biggest concerns highlighted by many, during their respective usage with GPT-3.5 was the chatbot coming up with all sorts of crazy, out-of-bounds answers and scenarios. And while OpenAI says that better “guardrails” have been put across in GPT-4, it remains to be seen how it performs in real-world scenarios, when it receives zillions of inputs from millions of users overtime.





{kind=link}